Joint Set
Disjoint set is a tree-shaped data structure. As the name suggests, it is used to deal with some disjoint merge and query problems. It supports two operations:
-
Find: determine which subset an element is in.
-
Union: merge two subsets into one set.
Warning
The disjoint set does not support the set separation. However, it supports the deletion of a single element in the set after modification (see UVA11987 Almost Union-Find for details). Dynamically creating nodes on segment tee can also realize persistent disjoint set.
Initialization¶
void makeSet(int size) {
for (int i = 0; i < size; i++) fa[i] = i; // i is in its own set
return;
}Find¶
First let's hear a story: Several families hold banquets and there are too many people because they usually live a long life. Due to long time separation and aging, these people gradually forget their relatives and only remember who their father is. The father of the oldest person (called "ancestor") has passed away, and he only knows that he is an ancestor. In order to determine which family they belonged to, they came up with a way, as long as they asked their father if they were ancestors, and asked them generation by generation until they asked their ancestors. If you want to know whether two people are in the same family, you only need to see whether the ancestors of the two are the same.
In this way of thinking, the find algorithm of disjoint set was born.
Here we offer a C++ implementation for your reference:
int fa[MAXN]; // record who is who's father, with special rules that the father of an ancestor is himself
int find(int x) {
// find the ancestors of x
if (fa[x] == x) // return if x is an ancestor
return x;
else
return find(fa[x]); // if not, then x’s dad asks x’s grandpa
}Obviously this will eventually return the ancestor of .
Path compression¶
The above way can indeed achieve the goal, but obviously the efficiency is too low. Why? Because we use too much useless information. Who my ancestors are and who my father is has nothing to do with it, and it is a waste of time to find generaion by generation. It’s better to let "me" be the "son" of my ancestors and obtain results. It doesn't even matter who the ancestor is, as long as this person can represent the family. Connecting each node on the path directly to the root, and this is path compression.
Here we offer a C++ implementation for your reference:
int find(int x) {
if (x != fa[x]) // x is not its own father, that is, x is not a representative of the set
fa[x] = find(fa[x]); // find the ancestors of x until you find a representative and compress the path along the way
return fa[x];
}See these two figures:
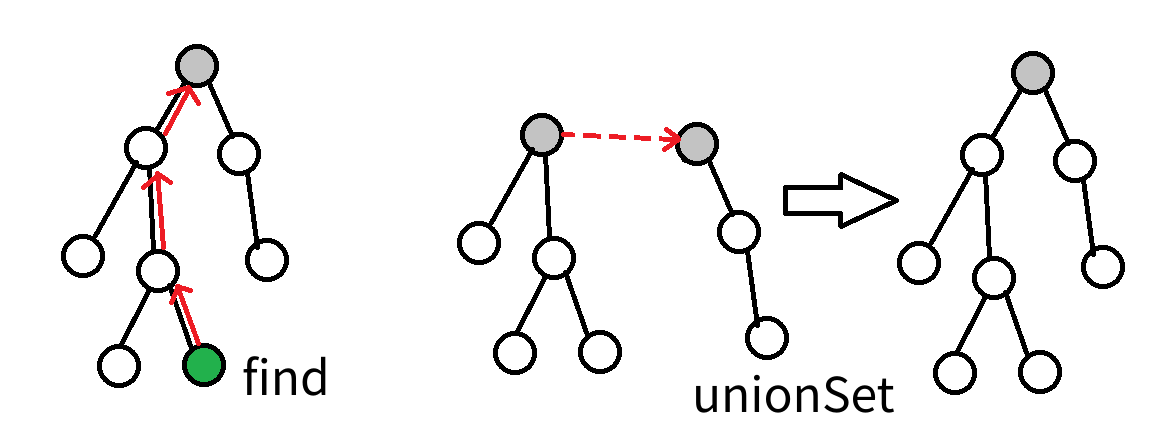

Union¶
At the banquet, the ancestor of one family suddenly said to another family: Our two families have such a good relationship, so what about merging into one family? The other family also gladly accepted.
As we said before, we don’t care who the ancestors are, so it only needs to make an ancestor to be the child of another one.
Here we offer a C++ implementation for your reference:
void unionSet(int x, int y) {
// merge the families of x and y
x = find(x);
y = find(y);
if (x == y) // do nothing if it was in the same family
return;
fa[x] = y; // turn x's ancestor into y's ancestor's son
}Heuristic merge (merging by rank)¶
One of the ancestors suddenly had an interesting idea: "Your family has fewer people. It is more convenient to move to our family because it would be too troublesome if we move there."
Since we only need to support the find and union operations of sets, when we need to merge two sets into one, no matter which set is connected to the other, we can get the correct result. However, different connection methods have different time complexity. Specifically, if we connect a set tree with a smaller number of nodes and depths to a larger set tree, obviously compared to another connection scheme, the next find operation takes less time (also would have better worst time complexity).
Of course, we don't always encounter situations where sets happen to be like what described above — the nodes and depth are smaller. In view of the fact that the two features of nodes and depth are easy to maintain, we often choose one of them as the evaluation function. Regardless of which one is selected, the time complexity is . For specific proof, please refer to the paper cited in references.
In the actual code of the algorithm competition, even if heuristic merging is not used, the code can often complete the task within the specified time. In Tarjan's paper [1], it is proved that the worst time complexity of not using heuristic merging and only using path compression is . In Yao Qizhi's paper [2], it is proved that without heuristic merging and only path compression, the time complexity is still on average.
If only heuristic merging is used instead of path compression, the time complexity is . Since a single merge of path compression may cause a large number of modifications, sometimes path compression is not suitable for use. For example, in the persistent disjoint set, segment tree divide and conquer + disjoint set, only heuristic merge is generally used.
Here is a C++ reference implementation, which uses the number of nodes as the evaluation function:
std::vector<int> size(N, 1); // record and initialize the size of the subtree to 1
void unionSet(int x, int y) {
int xx = find(x), yy = find(y);
if (xx == yy) return;
if (size[xx] > size[yy]) // ensure that the small ones merge into the big ones
swap(xx, yy);
fa[xx] = yy;
size[yy] += size[xx];
}Time complexity and space complexity¶
Time complexity¶
After using path compression and heuristic merging at the same time, the average time of each operation is only , where is the inverse function of Ackerman function, and its growth is extremely slow. That is to say, the average running time of a single operation can be considered as a small constant.
The Ackermann function, , is defined as:
The definition of the inverse Ackermann function is the inverse function of the Ackermann function, which is the largest integer such that .
The proof of the time complexity in this link.
Space complexity¶
Weighted disjoint set¶
We can also define certain weights on the edges of the disjoint set, and the calculations generated by the weight during path compression, so that we could solve more problems. For example, for the classic problem NOI2001 food chain, we can maintain the addition group on the edge in modulo 3.
Classic problems¶
NOTE: all problems except the last one are in Chinese. Please kindly use language translation tools if you would like to practice and we are working on introducing more English problems from different platforms
「NOI2015」Program automatic analysis
「NOI2002」Legend of the Galactic Heroes
Other applications¶
The Kruskal algorithm in Minimum spanning tree and the Tarjan algorithm in lowest common ancestor are both based on the disjoint set.
References¶
- [1]Tarjan, R. E., & Van Leeuwen, J. (1984). Worst-case analysis of set union algorithms. Journal of the ACM (JACM), 31(2), 245-281. ResearchGate PDF
- [2]Yao, A. C. (1985). On the expected performance of path compression algorithms. SIAM Journal on Computing, 14(1), 129-133.
- [3]Zhihu: Is there really a binary path compression optimization in the disjoint set? question link
- [4]Gabow, H. N., & Tarjan, R. E. (1985). A Linear-Time Algorithm for a Special Case of Disjoint Set Union. JOURNAL OF COMPUTER AND SYSTEM SCIENCES, 30, 209-221. CORE PDF
buildLast update and/or translate time of this article,Check the history
editFound smelly bugs? Translation outdated? Wanna contribute with us? Edit this Page on Github
peopleContributor of this article HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
translateTranslator of this article Visit the original article!
copyrightThe article is available under CC BY-SA 4.0 & SATA ; additional terms may apply.